|
Founder at Unify, where we're building neural routers to send each prompt to the best LLM. LinkedIn / Twitter / Medium / Google Scholar / Email |

|
|
|
 |
Guillermo Sanchez-Brizuela, Ved Patwardhan, Matthew Barrett, Paul Anderson, Mustafa Hani, Daniel lenton, NeurIPS, 2023 paper / video / code / docs Ivy enables the integration of code from one ML framework into another, speeding up development and also model inference. |
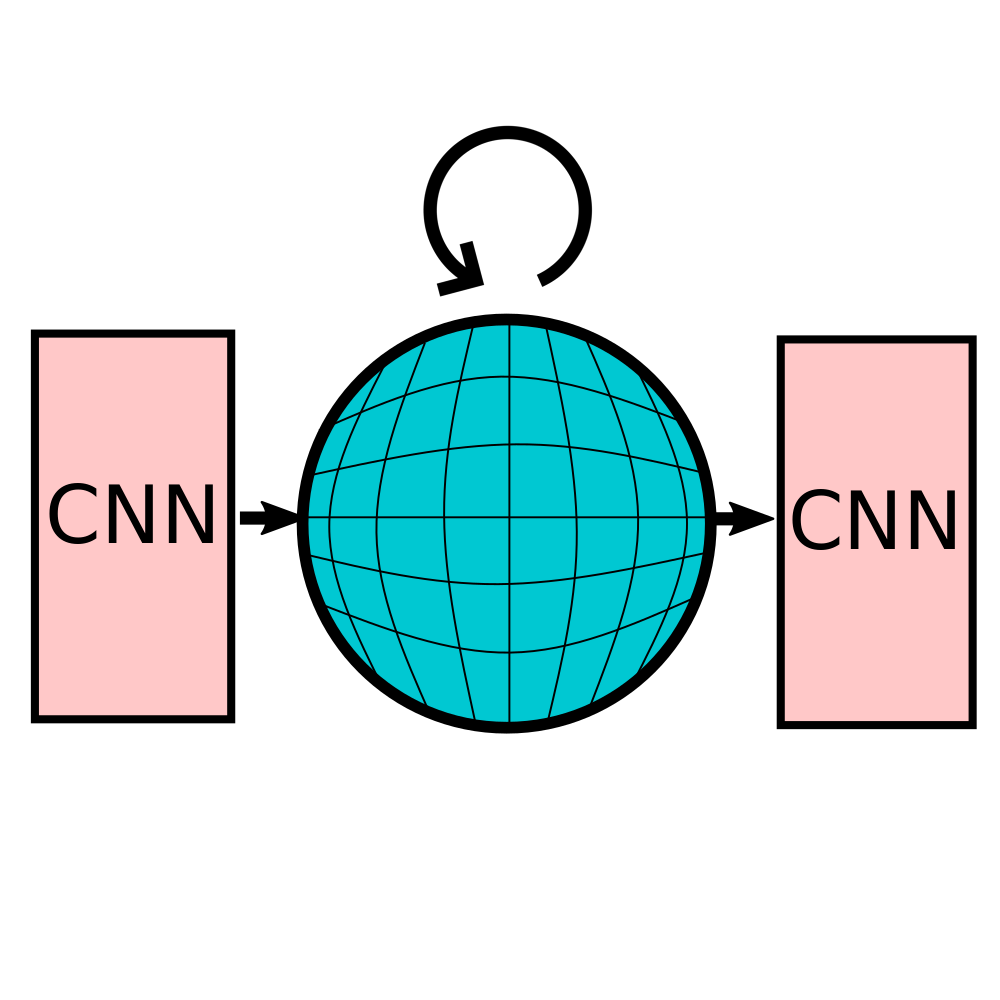 |
Daniel lenton, Stephen James, Ronald Clark, Andrew Davison International Conference on Learning Representations (ICLR), 2021 paper / video / code / project page ESM encodes the memory in an ego-sphere around the agent, enabling expressive 3D representations. ESM can be trained end-to-end via either imitation or reinforcement learning, and improves both training efficiency and final performance against other memory baselines on visuomotor control tasks. |
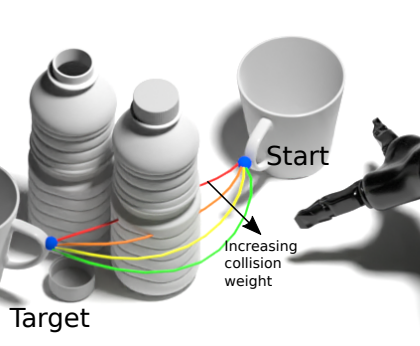 |
Michal Pandy, Daniel lenton, Ronald Clark International Conference on Intelligent Robots and Systems (IROS), 2021 paper / project page We demonstrate that challenging shortest path problems can be solved via direct spline regression from a neural network, trained in an unsupervised manner without requiring ground truth optimal paths for training. To achieve this, we derive a geometry-dependent optimal cost function whose minima guarantees collision-free solutions. |
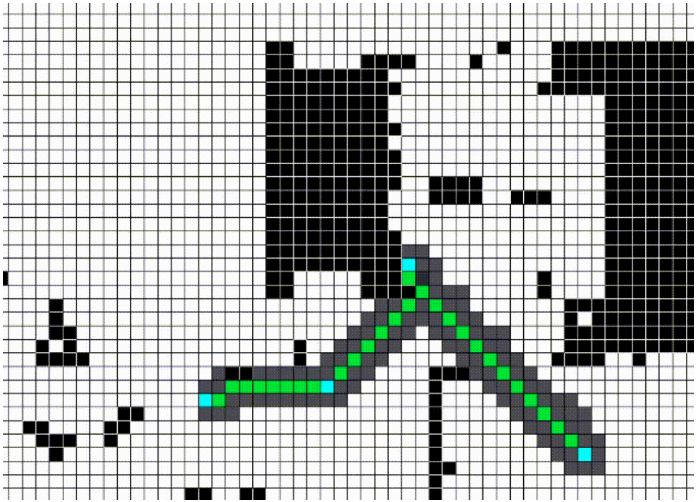 |
Alexandru-Iosif Toma, Hussein Ali Jaafar, Hao-Ya Hsueh, Stephen James, Daniel lenton, Ronald Clark, Sajad Saeedi, International Conference on Computer Vision and Robotics (CVR), 2021 paper / video / code / project page / Waypoint Planning Networks, or WPN, is a hybrid motion planning algorithm based on LSTMs with a local kernel, a classic algorithm such as A*, and a global kernel using a learned algorithm. WPN produces a more computationally efficient and robust solution than other learned approaches. |
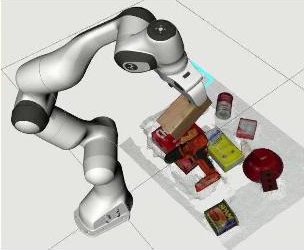 |
Kentaro Wada, Edgar Sucar, Stephen James, Daniel lenton, Andrew Davison Conference on Computer Vision and Pattern Recognition (CVPR), 2020 paper / video / code / project page MoreFusion makes 3D object pose proposals from single RGB-D views, accumulates pose estimates and non-parametric occupancy information from multiple views as the camera moves, and performs joint optimization to estimate consistent, non-intersecting poses for multiple objects in contact. |